General usage and file structure of Python Backend
The Python Backend project provides functionality for accessing inverter data, performing data processing tasks, and exposing these functionalities through a REST API. It connects seamlessly to a PostgreSQL database for storing and retrieving inverter data.
API
Technologies Used
- FastAPI: - A high-performance web framework, FastAPI, is used to build the REST API. It facilitates the definition of endpoints, handling of incoming requests, and returning of responses.
- OpenAPI: - Comprehensive API documentation is automatically generated based on the project’s code. This documentation clarifies the data accepted and returned by the API.
- SQLAlchemy: An Object-Relational Mapper (ORM), is used to simplify interaction with the PostgreSQL database. It allows for the definition of models representing tables and relationships.
Project Structure
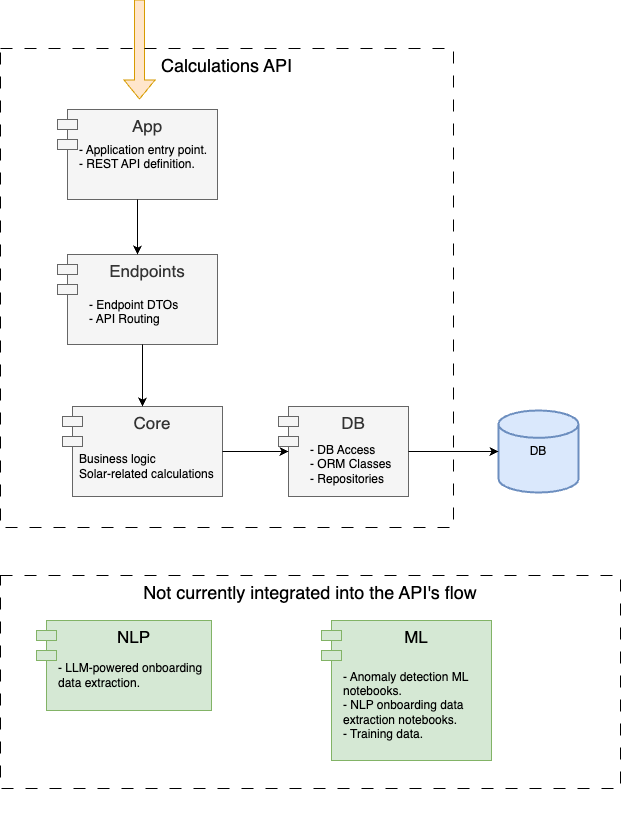
app/
├── db/ # Database-related components
│ ├── models.py # ORM models for database interaction
│ └── utils.py # Database access functions (data layer logic)
├── endpoints/ # API endpoints and request handling
│ └── solar/ # Endpoints specific to solar data management
├── core/ # Business logic and data processing
├── logs/ # Log files
├── main.py # Application entry point
└── database.ini # Configuration file for PostgreSQL connection details
Main Project Components
- App
- main.py: The application entry point, defines the API using FastAPI and sets up routing for incoming requests.
- logging.conf: Configures logging for debugging and monitoring purposes.
- database.ini: Defines connection details for the PostgreSQL database, ensuring secure access.
- DB
- models.py: Defines ORM models and schemas that represent tables and relationships in the PostgreSQL database.
- utils.py: Contains functions for connecting to the database, performing database operations (CRUD), and facilitating communication between the application and the database.
- Core: Houses the core business logic of the application. This module implements necessary data processing functionalities, such as calculations, transformations, or other manipulations.
- Endpoints
- solar: Contains files dedicated to handling specific API requests. Each endpoint file defines the input and output parameters of the endpoint, orchestrates calls to the appropriate functions in the DB and Core layers, and returns a meaningful response to the client.
Machine learning
This section implements the machine learning components employed for anomaly detection and client onboarding automation
Technologies Used
- IPython:: An interactive environment, is used for exploratory data analysis. IPython notebooks are used to experiment with the data, visualize it, and prototype machine learning models before deployment.
- scikit-learn: Provides a wide range of machine learning algorithms. In this project, scikit-learn is leveraged for the anomaly detection task. It offers various models suitable for the task.
- xgboost: Provides implementation of ensemble models based on the random forest algorithm.
- tensorflow: A flexible deep learning framework, is used for the development and training of more sophisticated neural network models.
- spacy: Used for client onboarding automation through its named entity recognition (NER) capabilities.
Proyect structure
app/
└───ml/ # Machine learning components
│ └───data/ # Training and testing data
│ └───notebooks/ # Jupyter notebooks for model development
│ │ └───anomaly_detection/ # Anomaly detection notebooks
│ │ │ ├── 1 - Data Preprocessing.ipynb # Prepares raw data for analysis
│ │ │ ├── 2 - Feature Engineering.ipynb # Creates informative features for the model
│ │ │ └── 3 - Model Training.ipynb # Trains and evaluates the anomaly detection model
│ │ └───nlp/ # Natural Language Processing notebooks
│ │ │ └── 1 - Data Preprocessing.ipynb # Prepares NLP data
│ └───models/ # Trained machine learning models
Notebooks
Anomaly Detection
Machine Learning for Solar Panel Performance Anomaly Detection
- Data Preprocessing:
- This notebook focuses on preparing the raw solar panel production data for further analysis and model training.
- Feature Engineering:
- This notebook builds upon the preprocessed data and focuses on crafting informative features that can be used by the machine learning model to identify anomalies.
- Model Training:
- This notebook utilizes the engineered features to train and evaluate different models in the task of anomaly detection.
NLP
This section outlines the Natural Language Processing (NLP) pipeline for streamlining client onboarding by automatically extracting key information from solar installation reports using a Named Entity Recognition (NER) model.
- Data Preprocessing:
- This notebook focuses on preparing the raw solar installation reports for efficient NLP processing.